Hello folks!
For those of you who are in charge of a large VoIP environment with multiple CUCM clusters, I dedicate this post. This is going to be a multi-part document, since the topic being covered is rather large and I want to be as detailed as possible.
The Environment
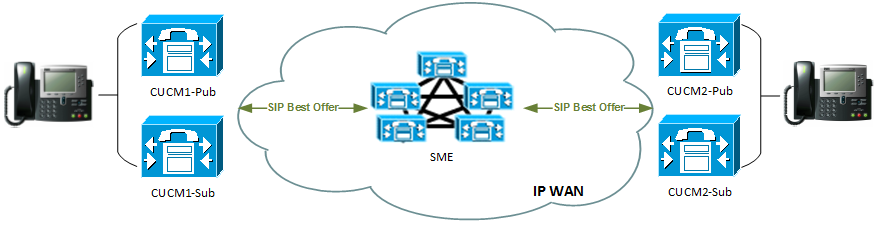
We are dealing with two CUCM clusters that have SIP trunks to Cisco SME cluster. In reality, the environment is a much larger one, consisting of 12 multi-node CUCM clusters scattered around the globe. I have intentionally simplified the topology to include just three CUCM clusters, with one of them being used as SME.
The Challenge
In this particular case, the client would like to implement end-to-end phone security (signalling and media encryption) on all endpoints that support it. Because the traffic is traversing SME, we need to make sure that the SIP trunks between CUCM and SME clusters are secure. In a traditional two-cluster scenario, all you need to do is to follow this awesome guide by Jason Burns, where we exchange CallManager.pem self-signed certificates between all nodes, configure SIP Trunk Security Profile and off we go. But imagine doing that certificate exchange with 12 multi-node clusters!
The Solution
We are going to use our own Enterprise CA to issue new CallManager certificates for all CUCM clusters and import the Root CA certs only to trust the issuer. Here’s the detailed guide on how to achieve just that.
Part 1: Preparing Enterprise CA and Issuing the Certs
Note: it is assumed that you have all the necessary rights to work with your Windows Server-based Certificate Authority.
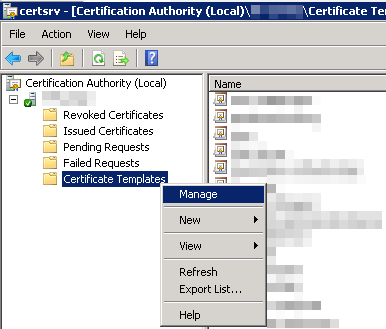
Step 1: Using Certificate Authority Add-In, connect to your Root or Subordinate CA, navigate to ‘Certificate Templates’, right-click and select ‘Manage’:
Step 2: In the ‘Certificate Templates Console’ that will open, right-click on any existing certificate and select ‘Duplicate Template’. When prompted, select ‘Windows Server 2003 Enterprise’ version for the duplicate.
Step 3: In the ‘Properties of New Template’ window, give certificate template a name (e.g. “CallManager”), choose validity period (higher is good, but note that the certificate validity period should be less than of the issuing CA’s), and put a check mark on ‘Publish certificate in Active Directory’ box:
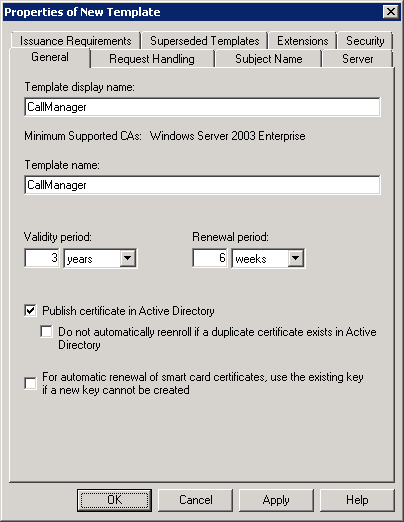
Step 4: Under ‘Request Handling’ tab, make sure that ‘Signature and encryption’ is selected for the certificate purpose and the minimum key size is 2048 or greater bits.
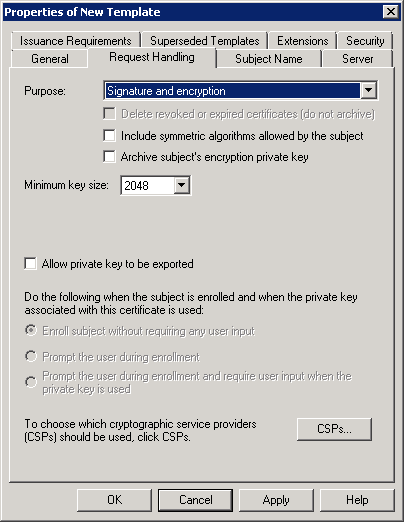
Step 5: Under ‘Subject Name’ tab, select the ‘Supply in request’ radio button:
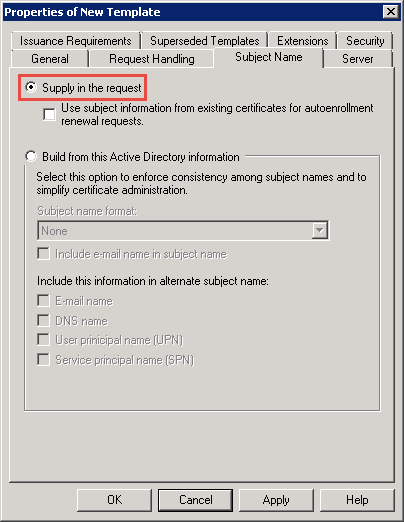
Step 6: Under ‘Extensions’ tab, click on the ‘Edit…’ button and ensure that ‘Client Authentication’ and ‘Server Authentication’ application policies are selected:
Step 7: Under ‘Security’ tab, make sure that your user account has the necessary permissions, allowing you to Read, Write, and Enroll certificates using this template.
Step 8: Leave all other values at their default and click “OK” to create the new certificate template. Close the ‘Certificate Template Management’ window and return to the ‘Certification Authority’ console.
Step 9: Back in the ‘Certification Authority’ console, right-click on the “Certificate Templates” and select ‘New’ -> ‘Certificate Template to Issue”. Select the new template that was created in the previous steps (“CallManager”):
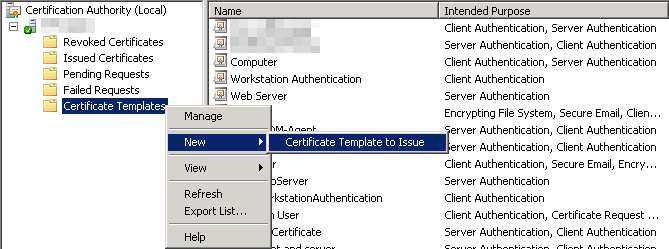
Now you are ready to issue the actual certificate for your CallManager clusters using CA’s web-based AD Certificate Services (https://your-CA-FQDN/certsrv).
Part 2: Requesting, Issuing and Installing CallManager Certificates
The following steps are required to be completed on all CUCM nodes, including the SME ones.
Step 1: Navigate to Cisco Unified OS Administration site of your first cluster’s publisher node (https://CUCM-1/cmplatform).
Step 2: Go to Security -> Certificate Management and click ‘Find’ to display a list of current certificates.
Step 3: To enable SIP trunk encryption, we are going to generate a new certificate request file (CSR) for CallManager certificate type, so click on ‘Generate CSR’, select ‘CallManager’ for the certificate purpose, select ‘Multi-server (SAN)’ for distribution type:
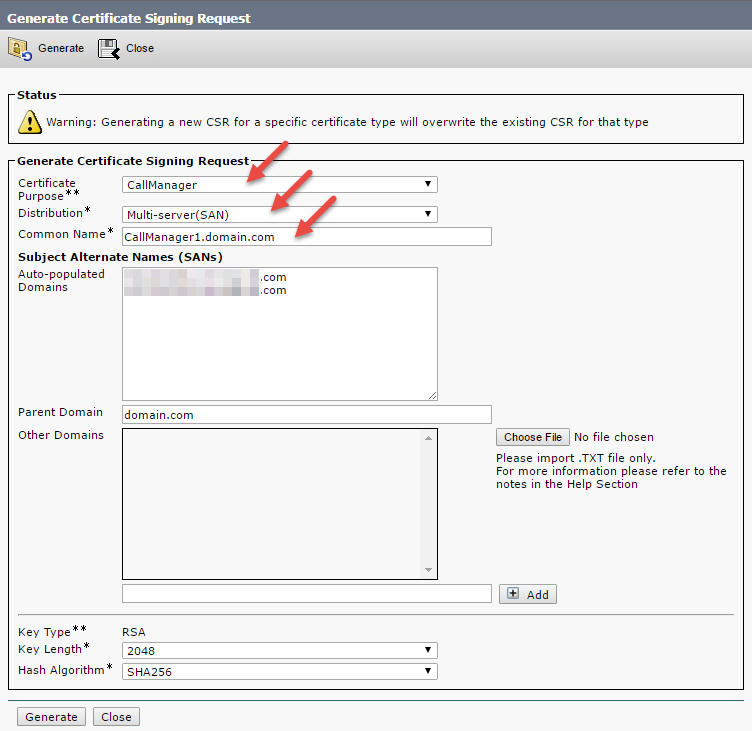
Note: for my Multi-Server (SAN) certificates, I typically edit the CN (Common Name) to match the Publisher’s FQDN. Why? This reduces the required number of SANs, which is important if you are using third-party CA that limits the number of alternative names for the cert.
Step 4: Download the newly-generated CSR, open it in notepad and copy the generated Base-64-encoded certificate request.
Step 5: Navigate to your CA’s Active Directory Certificate Services web-based UI (https://FQDN-of-your-CA/certsrv/), click on “Request a certificate” -> “Advanced certificate request” and paste the certificate request in the textbox. Select “CallManager” certificate template that was created in Part 1 of this guide and then click “Submit >”:
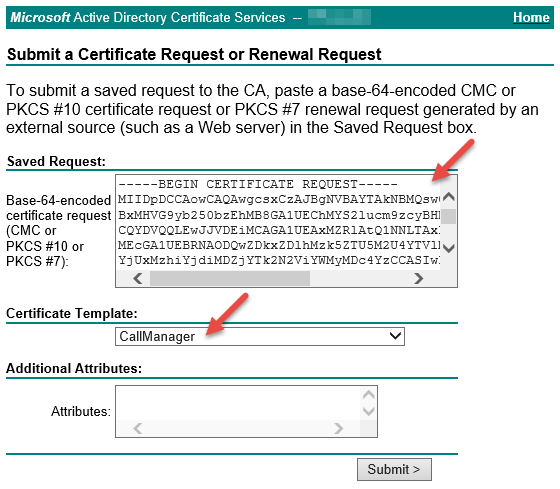
Step 6: Once the certificate has been generated, download it in Base-64-Encoded format.
Step 7: Back to CA AD Certificate Services Web GUI, click on “Home” link in the upper-right corner to return to the main page and click on “Download a CA certificate, certificate chain, or CRL” link. Select the current CA certificate, and ‘Base 64’ for the encoding method, then click “Download CA certificate”.
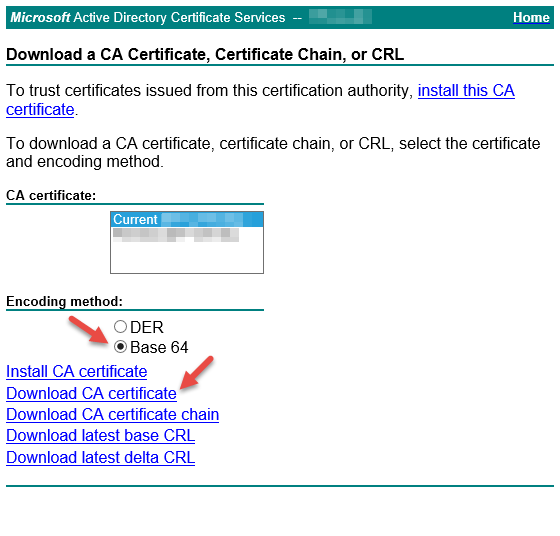
Important: If the certificate has been issued by your subordinate CA, you need to separate your Root CA certificate from Subordinate CA certificate. Here’s how:
- Open the CA certificate that was downloaded in Step 7 above and navigate to “Certification Path” tab.
- Select the “Root CA for [yourdomain]”, then click “View Certificate”:
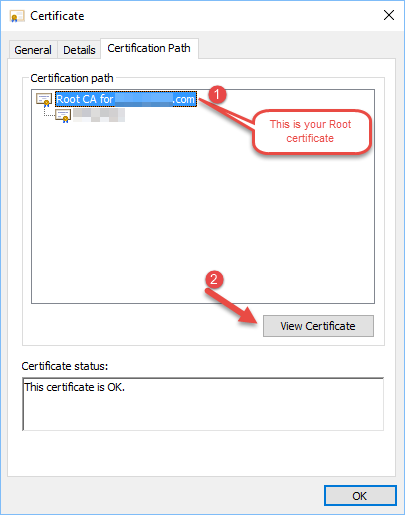
- In the new ‘Certificate’ window that will open, click on “Details” tab and then click “Copy to File…” button that would open Certificate Export Wizard.
- In the ‘Certificate Export Wizard’, click “Next” -> select “Base-64 encoded X.509 (.CER)” format and provide a path to save the file.
Step 8: Back to your CallManager’s OS Administration page, click on “Upload Certificate/Certificate Chain”.
- Upload the Root CA certificate as “CallManager-trust” type.
- If applicable, upload the Subordinate CA certificate as “CallManager-trust” type.
- Upload the CA-generated certificate as “CallManager” certificate.
Step 9: You will need to restart Cisco TFTP and CallManager services under Cisco Unified Serviceability page on all CallManager nodes in the cluster for the new certificate to take effect. Hold on to that just for now.
Part 3: Switching the cluster to Mixed-Mode
For the encryption to work on CallManager endpoints and trunks, you need to ensure that your CUCM clusters are switched from the default “Non-secure” mode to “Mixed-mode”. First, verify the cluster mode on all of your CallManager clusters by navigating to System -> Enterprise Parameters -> ‘Cluster Security Mode’:
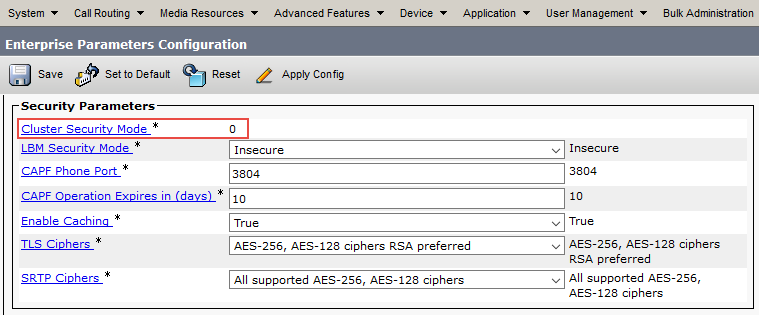
If the value is “0”, then the cluster is in “Non-secure” mode and need to be switched to “Mixed-mode” by following these steps.
Step 1: Open an SSH session with your CallManager Publisher in Cluster 1.
Step 2: Issue “utils ctl set-cluster mixed-mode” command:
admin: utils ctl set-cluster mixed-mode
This operation will set the cluster to Mixed mode. Do you want to continue? (y/n): y
Moving Cluster to Mixed Mode
Cluster set to Mixed Mode
Please Restart Cisco Tftp, Cisco CallManager and Cisco CTIManager services on all nodes in the cluster that run these services.
Step 3: Restart Cisco TFTP, Cisco CallManager and Cisco CTI Manager on all nodes in the cluster.
Important: If your cluster was already in Mixed-mode, you need to regenerate CTL certificates after replacing CallManager certificates on your CallManager cluster that we did in Part 2.
admin:utils ctl update CTLFile
This operation will update the CTLFile. Do you want to continue? (y/n): y
Updating CTL file
CTL file Updated
Please Restart the TFTP and Cisco CallManager services on all nodes in the cluster that run these services
If you are using Cisco Jabber in your environment and you omit the above step, the first indication that something went wrong after CallManager certificate replacement would be your Jabber’s phone services not working for any device types (CSF, TCT, etc.). If you review the jabber.log in Jabber’s PRT report, you may see the following errors:
2016-09-09 09:39:07,736 ERROR [0x00001e14] [ice\TelephonyAdapterServerHealth.cpp(66)] [jcf.tel.adapter] [CSFUnified::TelephonyAdapter::getConnectionIpProtocol] - No connected ConnectionInfo of type: [eSIP]. Could not determine connection IP Protocol
2016-09-09 09:39:07,736 DEBUG [0x00001e14] [\impl\TelephonyServerHealthImpl.cpp(279)] [jcf.tel.health] [CSFUnified::TelephonyServerHealthImpl::updateHealth] - updating health with serverType [CucmSoftphone] serverHealthStatus [Unhealthy] serverConnectionStatus [Disconnected] serverAddress [CUCM1.domain.com (CCMCIP)] serviceEventCode [UnknownConnectionError] transportProtocol [SIP] ipProtocol [Unknown]
This is fixed by regenerating CTL files and restarting TFTP and CallManager cervices on all nodes in the cluster.
We shall continue the setup with Part 4 in the next post. Stay tuned!